How big should a Lambda function be?
One of the core engineering principles within PostNL is the use of AWS serverless. It brings many benefits like scalability and cost savings, but it also brings new challenges to the table. For Lambda functions one of these challenges is the size of a function: is it best to use many, small Lambda functions or is it better to have a few, large ones? This blog post will give you an (opinionated) view on this topic based on the experience of one of the development teams within PostNL. Hopefully, the given considerations can help you in how you approach using Lambda functions.
How did we get here?
The question of how to partition your code is not something new, it’s a question that is already older than the cloud. So let’s first take a few steps back and see how we got here. For a long time, monoliths ruled the world of software. This was until people started cutting up the large, complex monoliths into smaller pieces: microservices were born. This worked nicely with the new trend of containers, where you could place one microservice in one container. Sometime later there was a new trend: serverless. This made it possible to cut up a microservice into even smaller parts (it even has a name: nanoservices). So the bottom line of this is that smaller is better, right? It allowed code to be more scalable, isolated, and easier to deploy. Let’s find out whether we should just follow the trend, or does this trend come to a stop.
The limits of a Lambda function
One thing I think is important to know before diving into this subject is knowing the hard limits of a Lambda function. The limits for a single function are a 15-minute timeout, 10,240 MB memory, and 10GB code size, see Lambda quotas. It looks like Lambda functions can handle large code bases, as long as the (monolithic) application doesn’t have long-running tasks of over 15 minutes or requires large amounts of memory.
This still doesn’t answer the question of how big a Lambda function should be, but it at least sets some boundaries for the discussion later on.
Smaller vs larger functions
With the necessary context in place, it’s now time to see what the options are and what their benefits are. Looking at the question again, it’s hard to make it specific. Saying that a Lambda function should always be 1GB in size doesn’t make sense. It makes more sense to see the question as a scale with one end being ‘as many small Lambda functions as possible’ and the other end being ‘as few big Lambda functions as possible’. So let’s see what the advantages of each extreme are.
Many small Lambda functions
Choosing this option means that you try to cut up Lambda functions as much as possible. The advantages of this are:
- The cognitive load of a single function is small. Since the code size in a function is smaller, it’s easier to understand the code and make changes. This makes it for example easier to optimise the code, resulting in faster and thus cheaper functions (since you pay for what you use).
- The impact of a wrong deployment is smaller since the rest of the Lambda functions still work.
- It’s possible to have clear (sub) domain boundaries between functions: a function often just does a single thing. This gives the flexibility to more easily move or replace them.
- Each function can be individually configured. One of these things is the memory of the function. This could save costs, since each Lambda function can be ‘power tuned’ to the right memory size. Another benefit is that each function gets it’s own IAM Role. That way it’s possible to have a very strict ‘least privilege’ setup.
- Each function can be individually monitored. This would make pinpointing a specific problem to a Lambda function easier.
- You’ll be less likely to run into any Lambda limits (memory, time-out) if you cut up a function and move some functionality to AWS services. One example of this is batch processing. If you try to solve this within your Lambda function, you’re likely to hit the memory or time-out limit at some point.
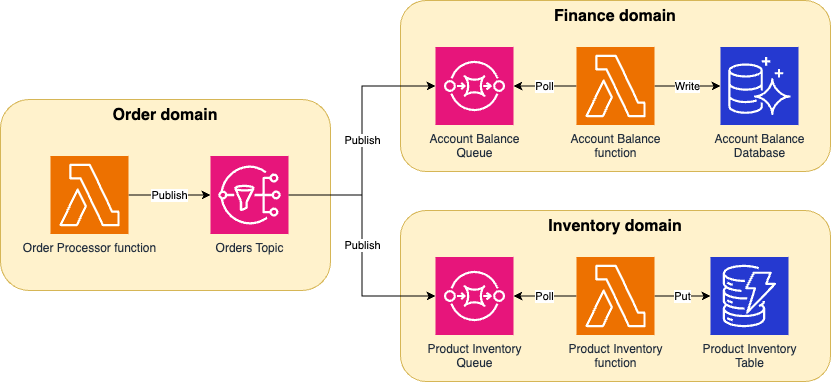
Example order processing application, where the size of the Lambda function reflects the size of the code it contains. It’s clear what the responsibility is of each Lambda function and to which domain it belongs. It would be possible to change one of the functions without directly impacting the others.
Few big Lambda functions
Choosing this option means that you try to combine Lambda functions as much as possible. The advantages of this are:
- The infrastructure is less complex since there are fewer functions. This makes the infrastructure easier to monitor and maintain.
- A single Lambda function contains more code of the application, making it easier to test and debug locally. If you want to write a test, there’s a bigger chance it just spans a single Lambda function. It’s easier and faster to write such a test than a test where you have to cover multiple Lambda functions and simulate or deploy AWS infrastructure.
- Deployments could be faster since you have to build, package, and deploy fewer Lambda functions.
- It’s easier to share code within a single Lambda function than over multiple Lambda functions. For the latter one, it’s often necessary to add some ‘library’ setup, including having to publish this library to a central package repository (like JFrog Artifactory) and then also consume it. Changing shared code via a library requires a lot of extra steps, while if the code is within a single Lambda it’s much simpler and faster.
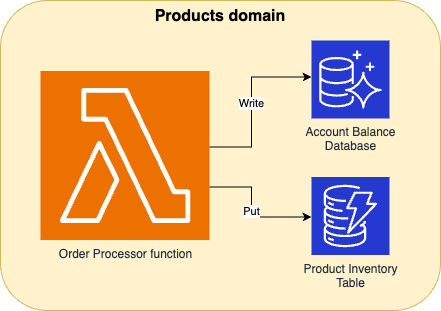
Example order processing application, where the size of the Lambda function reflects the size of the code it contains. The infrastructure for this setup is much simpler, and thus easier to build than the previous setup. The trade-off is that the code that the single function contains, is much more.
The actual choice
There are a lot of advantages to each setup and I think it all boils down to the following choice:
- Do you want the complexity to be in the infrastructure (many small Lambda functions) or in the software (few big Lambda functions)? This complexity means less flexibility and requires more effort (aka time).
The answer
Disclaimer: what now follows is a personal opinion.
The answer is different depending on the maturity of the project that you work on. In the beginning, when there are a lot of unknowns and value should be delivered quickly, the few big Lambda functions setup works best. It requires less effort and time to set up, causing the ‘Lead Time for Changes’ to be less. Given the uncertainties early on, changes are likely to happen. Later on, when patterns start to emerge, it’s easier to split up a single big Lambda function than to migrate code between many smaller ones. Having to do the latter one is very time-consuming, time that you don’t spend on delivering value.
At some point, when the application starts being used and when the domain is starting to become clear, is time to gradually cut up Lambda functions. This should solve some things that have been annoying for some time, like monitoring not being granular enough or some wrongly named functions. Of course, it would have been nice if you started with smaller functions straight away, then you wouldn’t have to refactor. From my experience, this is almost impossible, due to the many unknowns. You know you’re going to shoot yourself in your foot because you’re not going to get it right in one try. At least when working with bigger Lambda functions, the wound is less severe and easier to recover from.
Some final tips
So you probably think: I’m going to cut up these big Lambda functions, how should I cut them? These are some rules that help me decide on this:
- If the Lambda function has different input and output types, it should be split up per type. For example, if a Lambda function is triggered event driven by an SQS queue and triggered on a scheduled basis by EventBridge Scheduler, it should be cut up in a Lambda function for each trigger. This way there is less boilerplate code necessary (no logic needed to decide the type of input) and thus reduces the complexity of the code and the chance of bugs (picking the wrong trigger type). The same applies to the output type, for an SQS queue it might be necessary to return a batch response, while for an API Gateway, a rest response must be returned.
- Another rule is around the functional responsibilities of the function: each distinct functionality it does, should/could be its own Lambda function. This way it’s possible to identify the Lambda functions that are core to your application. For these, you want to be called in the middle of the night if something is wrong, while for others you don’t.
- Very similar to the previous rule, there’s also a rule for all technical responsibilities. If a single, big Lambda function has access to a large set of AWS resources (DynamoDB tables, S3 buckets, cross-account access, etc.), the security risk of such a function would be relatively high. If this function would be split up, it’s possible to also let each function have less privileges.
- Don’t mix (sub)domains in a single Lambda function. I think you could even go as far as saying that each Lambda function should just result in a single entity. If it’s about more than one entity, it’s a bad idea. For example: a Lambda function receives an order and then it reduces funds of the account of the customer and also reduces the amount of items in stock. This function does two things and should thus be split up.
Conclusion
The above summarises some of my learnings of Lambda functions so far. I’m curious as to what the opinion of other people is and how I will look at this in a few years. I would like to emphasize that there is no right or wrong as long as it’s a conscious choice between different advantages and disadvantages. It could, for example, be a good thing to split functions up from the beginning based on security reasons. The most important thing for me is that the design is set up in a flexible way, so it’s always possible to adapt the application to the journey of your team.